
tg-me.com/nlp_stuff/241
Last Update:
مدل MEND؛ ادیت سریع، فوری و انقلابی مدلهای زبانی
همانطور که مستحضرید، امروزه فرمان هوش مصنوعی در دست مدلهای از پیش آموزش دیده بزرگ نظیر GPTهاست و این مدلها تختهگاز در هر حوزهای مشغول تاختنند و تقریبا پرچمدار تمامی وظایفند. این مدلها دانش غنی گستردهای رو در خودشون دارند و حتی با عملکرد فوق انسانی خودشون باعث شگفتی میشوند. اما این مدلها هم در برابر گذر زمان بی عیب نیستند. GPT3 رو در نظر بگیرید. این مدل به هنگامی بر روی دادگان آموزشیاش تعلیم دیده که ترامپ هنوز رییس جمهور بوده. حال اگر همین الان از این مدل بپرسید که چه کسی رییس جمهور آمریکاست با پاسخ ترامپ ناامیدتون میکنه. چاره چیه؟
بدیهیترین چاره که به ذهن میرسه میتونه این باشه که این مدلها رو هر از گاهی روی دادگان جدید فاین تیون کنیم. اما در عمل نشون داده شده که این کار باعث اورفیت مدل بر روی این اندک (در قیاس با دادههای اولیه) دادههای جدید میشه و عملکرد کلی مدل هم آسیب میبینه. از طرفی اگر بخوایم این دادهها رو هم به دادههای قدیمی الحاق کنیم و مدل رو هر بار از اول روی همه این دادهها آموزش بدیم بایستی دارای عمر نوح باشیم که نشدنیه. برای این درد ادیت کردن مدل، تعدادی روش در سالهای گذشته پیشنهاد شدهاند. گیر اصلی این روشها عدم مقیاس پذیریشون به مدلهای بزرگی نظیر GPT است. حالا خانم چلسی فین که از کله گندههای متالرنینگ هستند اومدند و روشی تحت عنوان mend رو پیشنهاد دادند که حتی در مقیاس GPT هم قابل انجامه. به علاوه ایشون گفتند که این مدل بایستی سه خاصیت reliability و locality و generality رو ارضا کنه، به بیان سادهتر در مورد سوالهای جدید درست جواب بده، در مورد سوالهایی که ربطی به این سوالات جدید ندارند پاسخش عوض نشه و همچنین روی سوالات جدید بتونه خاصیت generalization داشته باشه.
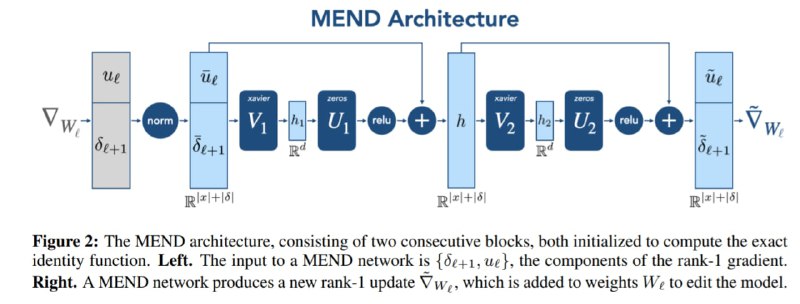
خانم فین برای حل این مساله پیشنهاد دادن که یک مدل عصبی به نام ادیتور داشته باشیم که وظیفه آموزش و تغییر دادن مدل پایه (همون GPTعه) رو داشته باشه. بر این اساس برای هر لایه L ام از وزنهای شبکه پایه یک مدل ادیتور g_l داریم. فرض کنید حالا متنهای جدید مربوط به این که بایدن رییس جمهور آمریکاست رو به مدل پایه میدهیم و عمل forward و backward را روی مدل انجام میدهیم. در حالت عادی بهینهسازی این گونه عمل میکردیم که در خلاف جهت گرادیان خام برای بهینهسازی شبکه پایه حرکت کنیم ولی خب این کار موجب همان اشکالاتی میشه که تو قسمت قبل صحبت کردیم. وظیفه مدل g_l این هست که با ورودی گرفتن گرادیانهای خام نسبت به وزنهای لایه Lام مدل پایه، یک جهتی رو برای بهینهسازی این وزنهای لایه Lام خروجی بده که سه خواسته ما در قسمت قبل رو برآورده کنه. در طی فرآیند آموزش این پکیج هم هر دور گرادیان تابع loss مدل پایه به ادیتور انتقال داده میشه و این شکلی ادیتور آموزش میبینه. (شهودش مثل اینه که چشمای دوستتون رو ببندید و ازش بخواید به سمت هدف تیراندازی کنه و در طول مسابقه با نتایج تیراندازیش یاد بگیرید چطوری به دوستتون راهنمایی برسونید و بهش بگید چه قدر مثلا به چه سمتی مایل بشه). حالا از طرفی چون که ماتریس وزنهای هر لایه L از مدل پایه به قدر کافی بزرگ هست، فین اینجا هم طرحی زده و این ماتریس با ابعاد d*d رو با تجزیه به فرم ضرب خارجی به رنک ۱ و نهایتا یک بردار با سایز d تبدیل کرده که همین باعث شده کلی از بار محاسباتی و زمانی قضیه خلاصی پیدا کنه (این تکه ریزجزییات زیادی داره اگه مشتاق هستید میتونید به مقاله مراجعه کنید)
اما بعد از توضیح معماری نوبت به ریزهکاریهای آموزش مدله. هر نمونه آموزشی که برای آموزش ادیتور بکار میره رو میشه به شکل یک تاپل ۵ تایی دید. چهار تا از این پنجتا، دو جفت x,y هستند که مربوط به سوالات جدید (نظیر رییس جمهور آمریکا کیه: بایدن) و (نظیر پرزیدنت ایالات متحده؟: بایدن) هستند که برای ارضای reliability و generality هستند. اسم این دو تا رو edit example و equivalance example میگذاریم. پنجمین عنصر هم یک سوال رندوم از مجموعه سوالاتیه که مدل پایه روی اونها پیش آموزش دیده (نظیر رییس جمهور روسیه؟: پوتین) که با توجه به این که حجم این سوالات خیلی بیشتر از سوالات جدیده احتمال بی ربط بودن این سوال رندوم با سوالات جدید تقریبا یکه. حالا در فرآیند آموزش، اول edit example به مدل پایه داده میشه و گرادیان خام تولید میشه. در گام بعدی ادیتور گرادیان خام رو میگیره و روی مدل پایه یک آپدیت انجام میده و بعد equivalance example به مدل پایه داده میشه و بر حسب loss روی این نمونه ادیتور آپدیت میشه! یک لاس هم برای یکی بودن پیشبینی مدل قبل و بعد از ادیت برای دادههای رندوم اضافه میشه.
تصویرهایی برای فهم مدل و دیدن نتایج هم پیوست شدهاند.
لینک مقاله:
https://arxiv.org/abs/2110.11309
#paper
#read
@nlp_stuff
BY NLP stuff
Share with your friend now:
tg-me.com/nlp_stuff/241